02-schema 和数据类型优化
数据类型的优化
- 更小的通常更好
尽量使用可以正确存储数据的最小数据类型,更小的通常更快,因为 占用更少的磁盘、内存和 CPU 缓存,并且 处理时需要的 CPU 周期更少,但是要确保没有低估存储值的范围 - 更简单的更好
简单数据类型的操作通常需要更少的 CPU 周期- 整形比字符操作代价更低,因为字符集的校验规则是 字符比较,比整型比较更加复杂
- 使用 mysql 自建类型而不是字符串存储日期和时间
- 使用整型存储 IP 地址
- 尽量避免 null
如果查询中包含可为 NULL 的列,对于 MySQL 来说很难优化,因为会使 索引、索引统计和值比较 更加复杂,但是通常情况下将 NULL 的列改为 NOT NULL 带来的性能提升较小,因此在设计时尽量避免即可
实际细则
整数类型
TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT分别使用8,16,24,32,64位存储空间。 尽量使用满足需求的最小数据类型字符、字符串类型
varchar:,长度可变,根据实际内容长度保存数据,最大长度 65535 个字节
- 使用最小的符合需求的长度
- varchar(n),n <= 255 时使用额外一个字节保存长度,n > 255 时使用额外两个字节保存长度
- varchar(5) 和 varchar(255) 保存相同内容,硬盘存储空间相同,但内存空间占用不用(为指定的大小)
- varchar 在 MySQL5.6 之前变更长度或从
长度 < 255->长度 > 255都会导致锁表
应用场景
- 存储长度波动较大的数据,例如文章
- 字符串很少更新的场景,每次更新后都会重新计算并使用额外存储空间保存长度
- 保存多字节字符,如汉字、特殊字符等
char:固定长度的字符串
- 最大长度 255
- 会自动删除末尾空格
- 检索效率、写效率都比 varchar 高,空间换时间
应用场景
- 存储长度波动不大的数据,如 md5 摘要
- 存储短字符串、经常更新的字符串
text:不设置长度,当不知道属性最大长度时适合使用
查询速度:char > varchar > text
BLOB 和 TEXT 类型
两者都是为了存储很大的数据而设计的字符串类型,分别采用 二进制 和 字符 方式存储
MySQL 把每个值都当成一个独立对象进行操作datetime 和 timestamp
不要使用字符串类型存储日期时间数据,日期时间类型通常比字符串占用的存储空间小
日期时间类型在进行查找过滤是可以利用日期来进行比对,并且有着丰富的处理函数,方便日期计算
使用 int 存储日期时间不如使用 timestamp 类型- datetime
占用 8 个字节,与时区无关,数据库底层时区配置对 datetime 无效,可保存到毫秒级别,可保存时间范围大 - timestamp
占用 4 个字节,时间范围 1970-01-01 ~ 2038-01-19,精确到秒,采用整型存储,依赖数据库设置的时区,自动更新值 - date
占用字节数比使用字符串、datetime、int 都小,只占用 3 个字节,可以利用日期时间函数进行计算,时间范围 1000-01-01 ~ 9999-12-31
- datetime
使用枚举类型替代字符串
MySQL 存储枚举类型十分紧凑,会根据列表值的数据压缩到 1 或 2 个字节中,MySQL 内部会将每个值在列表中的位置保存为整数,并在表的 .frm 文件中保存数字-字符串映射关系的查找表特殊类型数据
使用 varchar(15) 存储 IP 地址,它的本质是 32 位无符号整数而非字符串,可以使用 INET_ATON() 和 INET_NTOA() 函数在这两种表示方法之间转换
合理利用范式和反范式
范式
- 优点
- 范式化的更新通常比反范式快
- 数据较好的范式化后,重复的数据很少甚至没有重复
- 范式化的数据较小,可以放在内存中操作,速度较快
- 缺点: 通常需要进行关联
反范式
- 优点
- 所有数据都在同一张表中,可以避免关联
- 可以设计有效的索引
- 缺点: 表内冗余较多,删除数据可能造成表的某些有用信息丢失
注意事项
- 在企业中通常无法做到严格意义上的范式和反范式,一般需要混合使用
- 网站实例中,允许用户发送消息,并且部分用户是付费用户,现在想查看付费用户最近的 10 条消息,在 user 表和 message 表中都存储用户类型(account_type) 而不用完全的反范式化,避免了完全反范式化的插入和删除问题,即使没有消息的时候也不会丢失用户信息,同时减小了 user_message 表的大小,有利于高效获取数据
- 另一个从父表冗余一些数据到子表的理由是排序
- 缓存衍生值也是有用的,比如需要显示每个用户发了多少消息(论坛类型网站),可以没吃执行一个昂贵的查询来计算并显示,也可以在 user 表中建立一个 num_message 列,在用户发送消息时更新即可
- 案例
- 范式设计
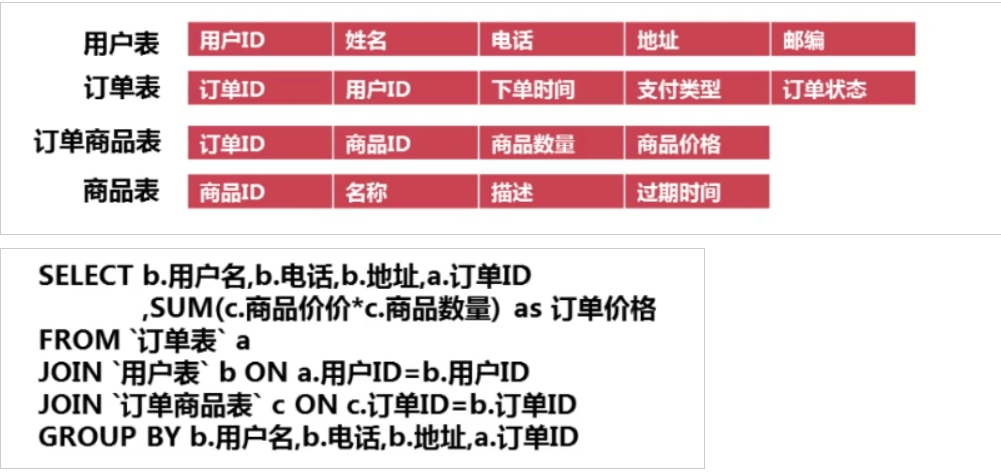
- 反范式设计

- 范式设计
主键的选择
- 代理主键:与业务无关的、无意义的数字序列
- 自然主键:事物属性中的自然唯一标识
- 推荐使用代理主键
- 不与业务耦合,更易于维护
- 在大多数的表/全部表中,通用的键策略能够减少需要编写的代码数量,减少系统总体运行成本
字符集的选择
- 纯拉丁字符能标识的内容,使用 latin1,可以减少大量存储空间
- 如果可以确定不需要存放多种语言,没有使用 UTF8 或其他 UNICODE 字符类型的必要,会造成大量存储空间浪费
- MySQL 的数据类型可以精确到字段,所以当需要在大型数据库中存放多字节数据的时候,可以通过对不同表不同字段使用不同的数据类型来较大程度减小数据存储量,进而降低 IO 操作次数并提高缓存命中率
存储引擎的选择

适当的数据冗余
被频繁引用且只能通过 join 2张(更多)大表的方式才能得到的独立小字段,由于每次 join 只为了取得某个小字段的值,join 得到的记录很大,会造成大量不必要的 IO,可以通过空间换时间的方案进行优化
在冗余的同时需要确保数据的一致性不遭到破坏,确保更新的同时冗余字段需要更新
适当拆分
当表中存在类似于 TEXT 或者 很大的 VARCHAR 类型 等大字段时,如果在大部分访问中都不需要这个字段,应该将其拆分到另外的独立空间,减少常用数据所占用的空间,这样可以使每个数据块中可以存储的数据条数增加,既减少物理 IO 次数,也能提高内存中的缓存命中率